|
1.はじめに
近年,人工知能(AI)は新規薬物ターゲットの発見から化合物スクリーニングまで,医薬品研究開発において数多くの応用が進んできた。しかし,現在の生成AI
技術の波は従来の補助ツールとは根本的に異なる。GPT-O1 のような大規模言語モデル(LLMs)は現在,人間が従事していた多くの複雑なタスクを直接実行可能になり,「アシスタント」から潜在的対象置換ツールへと進化している。製薬企業は生成AI
を戦略的優先事項と位置付け,臨床文書の起案,規制当局への申請,コンテンツ生成におけるイノベーションを推進している1)。例えばInsilico
Medicine のAI 設計薬候補は第II 相臨床試験の設計段階に成功裏に到達し,AI が医薬品開発ライフサイクル全体に統合されていることを実証している2)。初期段階の探索支援に限定されていた従来の応用とは異なり,生成AI
は現在バリューチェーン全体のワークフローの大部分を担う可能性を示している。この変革は医薬品開発におけるパラダイムシフトを示唆している:AI
は補助的支援から特定の役割における主要な実行主体へと移行しつつある。
(中略)
2.主要AI 技術の進展
生成AI の急速な進歩が産業変革の技術的基盤を築いている。OpenAI
の2024 年次世代モデルGPT-4o(「o」は「omni(全方位)」を意味)はマルチモーダルなリアルタイム推論機能を特徴とする。テキスト,音声,画像,動画入力を同時処理しつつ,テキスト,音声,視覚形式で出力を生成可能で,音声応答の遅延は約320ミリ秒まで短縮され,人間の会話速度に近づいている。GPT-4o
は英語テキストとコーディングタスクにおいてGPT-4 Turbo と同等の性能を維持しながら,多言語処理能力を大幅に強化し,API
コストを50%削減した3)。このブレイクスルーにより,製薬企業は会議議論のリアルタイム分析と推奨案提供など,より自然でコスト効率の良いAI
との相互作用が可能となった。
一方,Google DeepMind のGemini 2.0 は「エージェント時代」への参入を告げる。このモデルは画像と音声出力をネイティブでサポートし,組み込みツール使用機能を誇り,前世代を凌駕する性能を持つ(Googleintroduces
Gemini 2.0 : A new AI model for the agenticera)。記憶・推論・計画機能を備えた自律エージェントとして位置付けられるGemini
2.0 は,複雑なタスクを完了するためツールを自律的に起動できる(Googleintroduces
Gemini 2.0 : A new AI model for the agenticera)4)。Google
はProject Astra やMariner などのプロトタイプでGemini 2.0 のエージェント的応用シナリオを探求している。これは,AI
が会話応答を超え,高次元の指示に基づきタスクを自律的に分解し,情報を検索し,操作を実行する未来を予見させるもので,広範なクロスシステム・クロスドメイン連携を必要とする医薬品研究開発ワークフローに最適である。
欧米のテクノロジー大手を超え,中国発のAI イノベーターが台頭している。スタートアップのDeepSeek
は,最新の大規模言語モデル「DeepSeek-V3」と「R1」がOpenAI やMeta の最先端モデルに匹敵する性能を維持しながら,トレーニングコストを大幅に削減したと主張している(What
is DeepSeek and why is it disruptingthe AI sector?
| Reuters)。報告によれば,DeepSeek-V3のトレーニングコストは600 万ドル未満(Nvidia
H800チップ使用時)に抑えられた(What is DeepSeek andwhy is it
disrupting the AI sector? | Reuters)。さらに驚異的なのは,DeepSeek-R1
の運用コストがOpenAI の同等モデル比で20 〜 50 分の1 である点だ。この破壊的なコスト効率は業界の注目を集め,DeepSeek
のAI アシスタントが米国App Store 無料ランキングで1 位を獲得する原動力となった5)。こうしたコスト効率に優れたモデルの登場は,中小規模の製薬企業でも強力な生成AIの導入が現実味を帯びてきたことを示唆し,業界全体の知能化転換を加速させる可能性を秘めている。
結論として,GPT-4o のマルチモーダル・リアルタイム相互作用機能から,自律行動可能なGemini
2.0,コスト効率型のDeepSeek モデルに至るまで,AI 技術の主要な進歩は医薬品開発に前例のないツールキットを提供している。以下の議論では,これらのAI
システムが創薬バリューチェーン全体を前臨床段階から上市後管理までどのように再構築しているかを探る。
3.医薬品開発バリューチェーンの変容
開発候補化合物を特定した後,医薬品は臨床試験,規制当局への申請,上市後管理といった長期にわたるプロセスを経なければならない。生成AI
はこれらの段階に深く統合され,ワークフローを加速させるとともに,各機能部門の業務方法を変革しつつある。
3.1 臨床開発段階:IND 申請から臨床試験管理まで
候補薬が臨床試験に入る前に,研究開発チームは治験用新薬申請(IND/CTA)書類を作成する必要がある。これには研究者向け概要書(IB)や臨床試験計画書といった複雑な資料が含まれる。従来は数ヶ月を要したこれらの書類作成が,AI
によって大幅に短縮可能となった。大規模言語モデルは膨大な科学文献と過去プロジェクトデータを分析し,標準化されたテンプレートを用いて初稿のプロトコルや要約を自動生成できる。
研究によれば,適切なプロンプティングにより,LLM は広範な情報を統合してプロトコル草案を自動入力でき,医療ライターのように文書を生成可能だ。高品質のトレーニングデータを与えると,専門家が最小限の修正を加えるだけで基準を満たすレベルの草案精度を達成する2)。これは従来,ジュニアスタッフが草案を作成し上級者がレビューするモデルに類似しているが,AI
アシスタントは瞬時にデータ検索と初期草案作成を完了できる。報告によると,一部の製薬企業では臨床試験プロトコル草案作成に生成AI
を導入し,準備期間を劇的に短縮している。例えばある企業は,AI を活用してプロトコル作成と試験対象者選定タスクを自動化することで臨床試験準備期間を数ヶ月から数日に圧縮した実績を持つ6)。
臨床開発オペレーションの領域においても,AI は同様に変革を推進しています。適切な臨床試験施設の選定と十分な被験者募集は試験成功の鍵となりますが,依然として時間とコストを要する課題です。AI
予測エンジンは試験プロトコルを解読し,対象選定基準を理解した上で,歴史的データベースから最適な臨床試験施設をインテリジェントにマッチングできます。現在のモデル性能は手作業を完全に凌駕するには至っていませんが(利用可能なデータ不足が制約),高品質な施設パフォーマンスデータの学習利用が進むにつれ,AI
の施設選定と患者募集における精度は継続的に向上するでしょう2)。患者募集では,AI
が電子医療記録や医療データベースから適格患者を自動スクリーニングし,募集速度を予測,潜在的登録ボトルネックを特定できます。NatureDigital
Medicine の研究によると,AI 最適化された患者募集は試験コストを約70%削減し,募集期間を最大40%短縮可能と示されています6)。これは重要な臨床試験の加速化に大きな意味を持ち,新薬の検証段階への迅速な移行を可能にします。
(中略)
3.2 登録・申請フェーズ:NDA/BLA 提出と規制当局対応
重要な臨床試験を完了した新薬は,登録・申請フェーズ(FDA
へのNDA 提出,EMA へのMAA,中国におけるNDA/BLA 申請など)に移行します。この段階では膨大な文書作成と規制当局との対話が必要となり,生成AI
が卓越した能力を発揮します。
メディカルライティングチームは従来,臨床試験および非臨床試験の包括的なデータ概要を含む数千ページに及ぶ申請資料を作成する必要がありました。生成AI
は申請書類の草案を自動生成することで,ライターの負担を大幅に軽減できます。内部データベースから研究結果を抽出し,統計分析表を参照し,外部文献やガイドラインを引用して,臨床概要,安全性要約,薬力学概要などのCTD
モジュールの内容を編纂可能です。LLM は文脈理解とナラティブの一貫性維持に優れており,複数文書間の情報整合(患者集団の記述や主要データの章間整合性など)を確保することで,手動校正の労力を削減します。さらに最新の規制ガイドラインを統合することで,ライターに規制当局の関心事項を含めるよう警告し,情報欠落による追加照会を回避できます。
(中略)
3.4 AI エージェントの役割
医薬品開発の各段階におけるAI の可能性を最大限に活用するためには,第一原理に基づいてタスクを再検証・分解し,AI
をプロセス横断型インテリジェントエージェントとして位置付けることが重要です。従来,医薬品R&D
は専門機能ごとに分断され,各部門が独立したワークフロー構成要素を処理してきました。しかしAI
エージェントは,タスクをその根本目的から捉えることで部門の垣根を超越します。このパラダイムでは,複雑なタスクをAI
が理解・実行可能な原子単位のステップに分解し,AI エージェント間の自律的連携によるワークフロー完遂を可能にします。
例えば臨床試験プロトコル策定(その中核目的は既存データに基づく科学的に健全な研究計画の作成)において,第一原理アプローチでは次の要素に分解されます:疾患ドメイン知識の調査,過去の試験設計の参照,候補薬の特性と非臨床データの統合,プロトコル文書の最終化。AI
エージェントはこれらのステップを自律的に実行可能です: 最新の医学文献やガイドラインを外部検索して疾患・治療のコンテクストを把握,内部ナレッジベースを検索して類似試験の過去プロトコルと教訓を取得,言語生成能力を駆使してプロトコルの各セクション(背景・目的・設計・エンドポイント等)を起草しつつ標準テンプレートと用語を自動入力。この過程でAI
は継続的に規制適合性を検証(例:エンドポイント定義が規制要件に合致しているか確認)。投与量計算や統計推定が必要な場面では,組み込み分析ツールを起動し結果を直接プロトコルに統合します。このような段階的自律実行を通じ,AI
エージェントは「万能プロジェクトアシスタント」として高品質な試験プロトコルを自立生成可能となります。
(中略)
4.将来のトレンドと課題
生成AI が製薬開発プロセスに深く浸透するにつれ,より「AI
ネイティブ」なアーキテクチャとパラダイムが出現するでしょう。第一に情報インフラの再構築が挙げられます。従来のIT
システムでは,各機能部門ごとに分断されたデータベースとアプリケーションが展開されることが一般的でした。対照的に,AI
ネイティブアーキテクチャはAI 主導の業務運営を提唱し,データとアプリケーションの高度な統合を要求します。例えばMIT
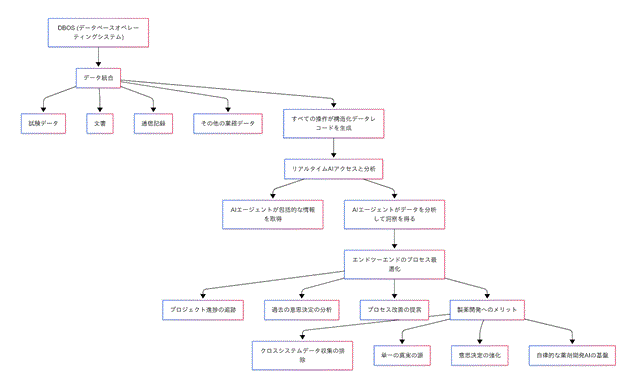
のデータベースパイオニアStonebraker が提案したDBOS(Database Operating
System)――オペレーティングシステムをデータベース上に構築し,全ての業務データとログ操作の保存・管理を統一する概念です11)。このアーキテクチャ下では,あらゆる操作が構造化データレコードを生成し,AI
によるリアルタイムアクセスと分析を可能にします。製薬企業にとってこれは,試験データ・文書・コミュニケーション記録などが統合プラットフォームに集約され,AI
が包括的な情報を検索・分析してエンドツーエンドのプロセス最適化を実現することを意味します。AI
エージェントがプロジェクト進捗や過去の意思決定を理解する必要が生じた際,複数システムに跨るデータ収集が不要になります――単一のデータベースオペレーティングシステムが統合された全情報を包含しているからです。これが真に自律的な創薬AI
の基盤を築きます。
図1 DBOS における未来の製薬開発
第二に,超大規模モデルと文脈処理能力がワークフローを変革します。将来のLLM(次世代Gemini
やその他の兆パラメーターモデル等)は拡張された文脈ウィンドウと強化された推論能力を備え,新薬開発プロジェクト全体の資料を一括処理可能になるでしょう。例えばGoogle
のGemini は100 万トークンの文脈ウィンドウを提供すると伝えられており(get access
to Google'smost capable AI models... - Gemini
Advanced)12),AIが全てのプロジェクト文書とデータセットを「忘れる」ことなく精査できます。これによりAI
はより包括的な計画立案と意思決定支援が可能に――全ての臨床試験結果を統合して新たな試験設計を最適化したり,数十社のプロジェクトから得た知見を活用して現在の取り組みに戦略的提言を提供したりできます。超大規模モデルは更に強力なマルチタスク処理能力と人間の意図理解を備え,人間とAI
の相互作用をより自然で効率的にするでしょう。
しかしながら,輝かしい展望を描く一方で,課題と制約にも直面しなければなりません。第一に技術的課題――AI
モデルの能力が増大しているとはいえ,信頼性と正確性の向上が依然として必要です。医療・規制分野ではエラーに対する許容度がゼロであり,AI
生成コンテンツの不正確さはコンプライアンスや安全性リスクにつながりかねません。現在のLLM
は「幻覚(hallucination)」問題を抱えており,もっともらしいが虚偽の内容を生成する可能性があります。これは規制文書の起草時に特に危険であり,厳格な検証プロセスの導入が不可欠です。この課題に対処するため,企業はAI出力に対する検証・監査メカニズムを確立する必要があります――手動レビュープロセスの導入,セカンダリアルゴリズムによるクロスチェック,エラー原因を特定するためのトレーサビリティ措置などが含まれます。
データとプライバシーの問題も主要な課題を提起しています。AI の効率的な運用は高品質なビッグデータに依存しますが,医薬品開発データには企業秘密や患者のプライバシーが含まれることが多々あります。AI
を活用しながら機密情報を保護するにはどうすべきでしょうか?一方では,内部ナレッジベースの非識別化処理とアクセス制御が必要です。他方では,データをパブリッククラウドモデルに送信するよりも,大規模モデルのオンプレミス展開を優先することで,データ漏洩リスクを軽減できます。規制当局もこの問題に注力しており,例えばEU
のAI 法は医療AI をハイリスク用途に分類し,厳格なデータ管理と透明性の遵守を要求しています。製薬企業はAI
導入時に規制適合性を確保する必要があり,製品安全性モニタリングや臨床意思決定支援における応用では事前審査・届出が必要となる可能性があります。
規制認可とコンプライアンスも重大な課題です。現在,世界中の規制当局はAI 生成コンテンツの受け入れ態勢を模索中です。AI
が作成した臨床報告書が人間の作成書類と形式的に同一に見えても,規制審査官は生成プロセスと品質管理措置の説明を要求する可能性があります。FDA
などの機関は医療製品ライフサイクルにおけるAI 応用に注目を強め,ガイダンス原則の策定を開始しています。例えばFDA
は医療機器ソフトウェアのAI/ML 変更に関する草案ガイダンスを発表し,AI モデル変更の規制枠組みを提案しました。同様に,医薬品開発プロセスではAI
を多用する企業が,システム文書内に対応する標準業務手順書(SOP)を確立し,AI 使用シナリオ,人と機械の相互作用方法,誤り修正ワークフローなどを明記し,監査要件を満たす必要があります。責任の所在問題も明確化が必要です:AI
生成の申請文書に誤りがあった場合,責任はAI 自体ではなく使用者に帰属します。従って企業はAI
出力を徹底的に検証し,責任を負担する必要があり,「AI の誤り」に帰するわけにはいきません。
◆本稿の全容は「月刊PHARMSTAGE」2025年4月号 本誌でご覧ください◆
月刊PHARMSTAGEのホームページはこちら
https://www.gijutu.co.jp/doc/magazine_pharm%20stage.htm
参考文献
参考文献
1)Applied Clinical Trials (n.d.).“ How Medical Writing
and Regulatory Affairs Professionals Can Embrace
and Deploy Generative AI at Scale.”
Retrieved from: https://www.appliedclinicaltrialsonline.com/view/medical-writing-regulatory-affairs-professionals-embrace-deploy-generative-ai
2)Applied Clinical Trials (n.d.).“ AI Already Starting
to Deliver Faster,Safer, More Effective Clinical
Trials.”
Retrieved from: https://www.appliedclinicaltrialsonline.com/view/ai-faster-safer-more-effectiveclinical-trials
3)OpenAI (n.d.).“ Hello GPT-4o | OpenAI.”
Retrieved from: https://openai.com/index/hello-gpt-4o/
4)Google DeepMind (n.d.).“ Google introduces Gemini
2.0: A new AImodel for the agentic era.”
Retrieved from: https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/
5)Reuters (n.d.).“ What is DeepSeek and why is it
disrupting the AI sector?”
Retrieved from: https://www.reuters.com/technology/artificial-intelligence/what-is-deepseek-why-is-it-disrupting-ai-sector-2025-01-27/
6)Clinion (n.d.).“ AI in Clinical Trials: Key to
Accelerated Timelines & Reduced Costs.”
Retrieved from: https://www.clinion.com/insight/ai-in-clinical-trials-key-to-accelerated-timelines-reduced-costs/
11)BigDataWire (n.d.).“
Stonebraker Seeks to Invert the Computing Paradigm
with DBOS.”
Retrieved from: https://www.bigdatawire.com/2024/03/12/stonebraker-seeks-to-invert-the-computing-paradigm-with-dbos/
12)Gemini Advanced (n.d.).“ Get access to Google
s most capable AImodels … - Gemini Advanced.”
Retrieved from:https://gemini.google/advanced/?hl=en
|

